
Tabla de contenidos
1. Introducción
En este artículo, crearemos las imágenes que contendrán el MQTT broker, los frontales que atenderán las peticiones de nuestros usuarios, y el backend que se encargará de almacenar datos y conectarse con la base de datos de RDS. Todo esto lo haremos usando docker para constuir las imagenes i subirlas a un repositorio versionado.
Antes de nada pero, puede que alguna de las piezas de sonfware mencionados anteriormente no te suene, te dejo por aqui una brebe explicaciópn de que hace cada pieza.
¿Qué es un MQTT Broker?
MQTT (Message Queuing Telemetry Transport) es un protocolo de mensajería que se utiliza para la comunicación entre dispositivos IoT. Un MQTT Broker es una pieza clave en la comunicación MQTT, ya que és responsable de gestionar las conexiones de los clientes, recibir y procesar los mensajes publicados por los clientes, y entregar estos mensajes a los suscriptores que se suscriben a los temas (conocidos como topics) correspondientes.
La arquitectura de MQTT se compone de tres elementos principales:
- Cliente MQTT: Puede ser un dispositivo IoT, un servidor o una aplicación.
- Broker MQTT: Actúa como intermediario entre los clientes y gestiona la distribución de mensajes.
- Topics: Son los canales de comunicación a los que los clientes pueden suscribirse o publicar mensajes.
Un ejemplo de un broker MQTT es Mosquitto MQTT, un servidor de mensajes MQTT de código abierto que se utiliza para implementar el protocolo MQTT en aplicaciones IoT. A pesar de que AWS tiene si propio MQTT broker llamado AWS IoT Core, usaremos mosquito con tal de crear una PoC con comunicación entre pods.
¿Que es RDS?
¿Que es docker?
Docker es una plataforma que permite a los desarrolladores construir, empaquetar y distribuir aplicaciones en contenedores.
Un contenedor es una unidad estándar de software que empaqueta el código y todas sus dependencias para que la aplicación se ejecute de manera rápida y confiable de un entorno informático a otro. Es decir, nos da igual que por debajo se este ejecutando en Windows, Ubuntu, AMazon Linux 2023 o cualquier otra distribución de sistema operativo entre otros.
En nuestro caso lo usaremos para empaquetar nuestro codigo (mqtt broker, frontend y backend) para que luego pueda ser usado en EKS.
2. Generemos las imágenes personalizadas para nuestro EKS
Para “compilar” las imágenes tendremos que realizar un par de acciones.
- Primero necesitaremos abrir docker o docker desktop. Para asegurarnos de que está corriendo, ejecutaremos “docker -v”.

- Después descargarás y extraerás el zip en una carpeta.
- Vamos a compilar por ejemplo la imagen de frontend, ya que es lo mismo para las otras imágenes. Iremos a la carpeta “Frontend/Image” y abriremos un terminal.
- En el terminal escribiremos “docker build -t kubernetes-article-frontend .” y nos construirá la imagen de la carpeta donde estamos.

ERRORES COMUNES
Si nos aparece un error como el de la imagen inferior, significa que tenemos que iniciar docker. Asegurate de que esta corriendo.

- Nos esperaremos a que la imagen termine de crearse.
- Una vez se haya terminado de crear la imagen, comprobaremos que realmente existe ejecutando “docker images –all”.

- Haremos lo mismo con las otras imágenes (cambia los nombres, según lo que estés creando) y comprobaremos que se han credo todas.

- Ya tendremos las imagenes listas para poder usarse en EKS.
3. Como subir las imágenes personalizadas a ECR
3.1 Creando los repositorios en ECR
A pesar de que podemos usar otros repos para las imágenes como DOCKER HUB, en este caso almacenaremos las imagenes en AWS Elastic Container Repository.
- Iremos a AWS y buscaremos ECR en la barra de búsqueda superior. Una vez dentro nos colocaremos en “Private registry” -> “Repositories” y le daremos a “create repository”.
MUY IMPORTANTE: Nos tenemos que situar en PRIVATE para que la imagen sea privada. Si nos colocamos en Public registry, la imagen será pública para todo el mundo y cualquiera podrá usarla.
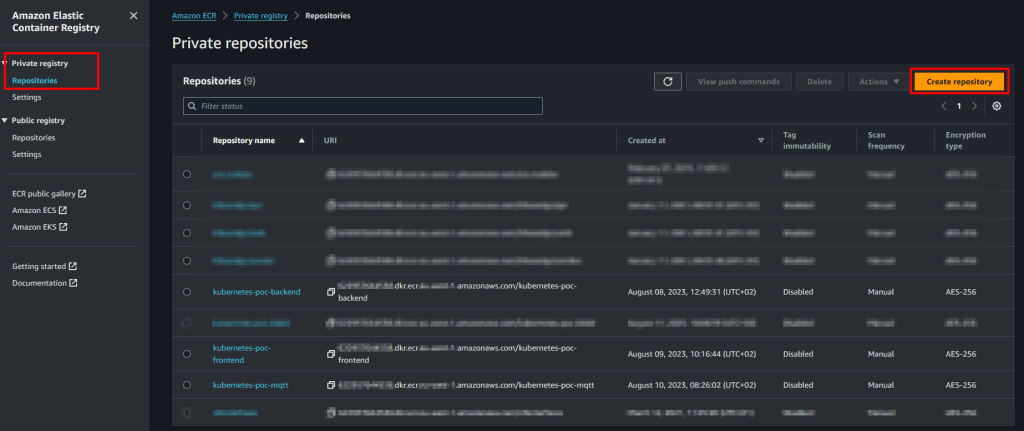
- Cuando creamos el repositorio, dejaremos seleccionado “Private”. En “repository name” introduciremos el nombre que le queremos dar al repositorio (por ejemplo, “eks-test-cluster/frontales”). Dejaremos “Tag immutability” desactivado.
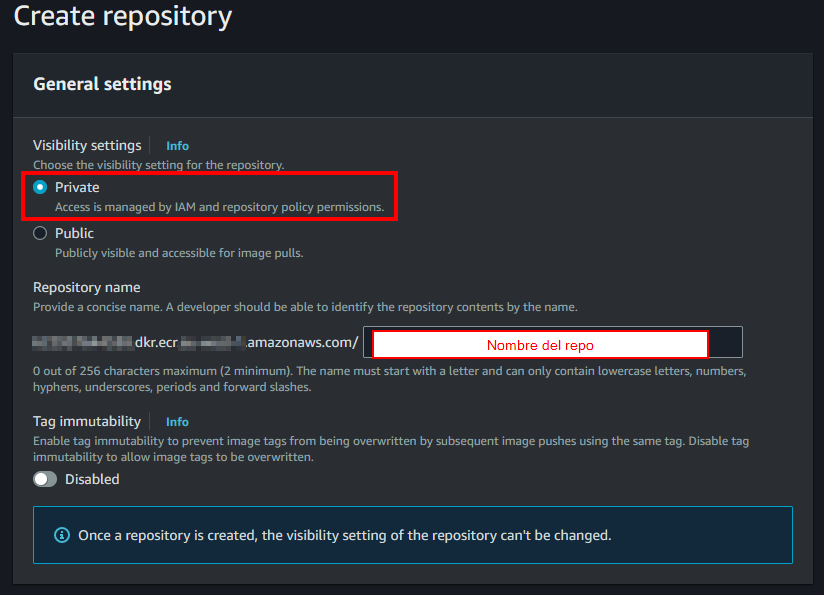
- Dejaremos des-seleccionado el scan on push. Sería una buena práctica tenerlo activado, pero puede incurrir en costes. También dejaremos KMS desactivado. Finalmente, le daremos a “Create repository”.
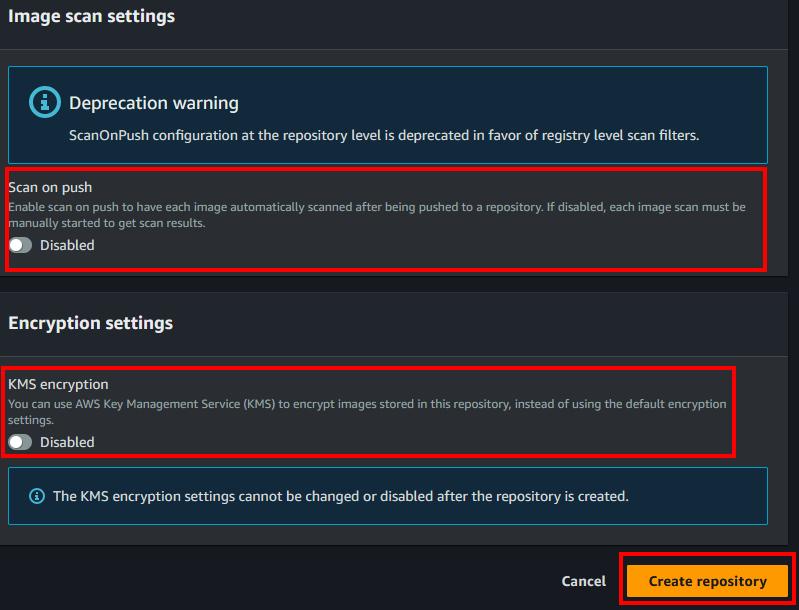
- Repetiremos estos pasos 2 veces más, puedes poner los nombres “eks-test-cluster/mqtt-broker” y “eks-test-cluster/backend”.
3.2 Compilando y subiendo las imágenes a ECR
- Si no tienes configurado tu rol en el terminal AWS CLI, tienes que volver a configurarlo. En el artículo 3 te explicamos como.
Ojo: Este usuario debe tener permisos para subir imágenes a ECR, si te encuentras con problemas debes añadir la política “arn:aws:iam::aws:policy/EC2InstanceProfileForImageBuilderECRContainerBuilds” a tu rol. - Comprobaremos que tenemos docker funcionando.
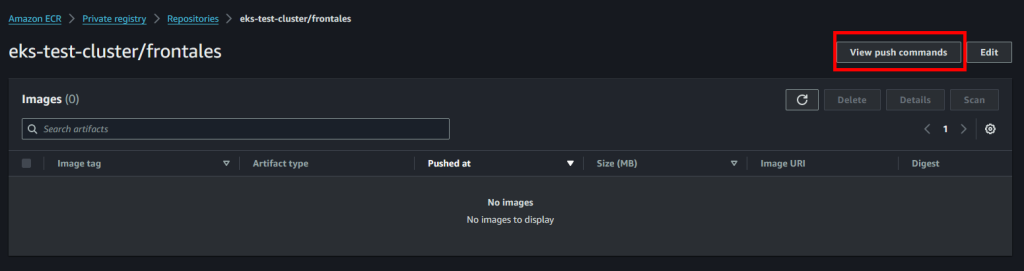
- Entraremos al repositorio de ECR cuya imagen queremos subir, por ejemplo el de frontend.
- En la parte superior derecha, seleccionaremos “View push commands”.
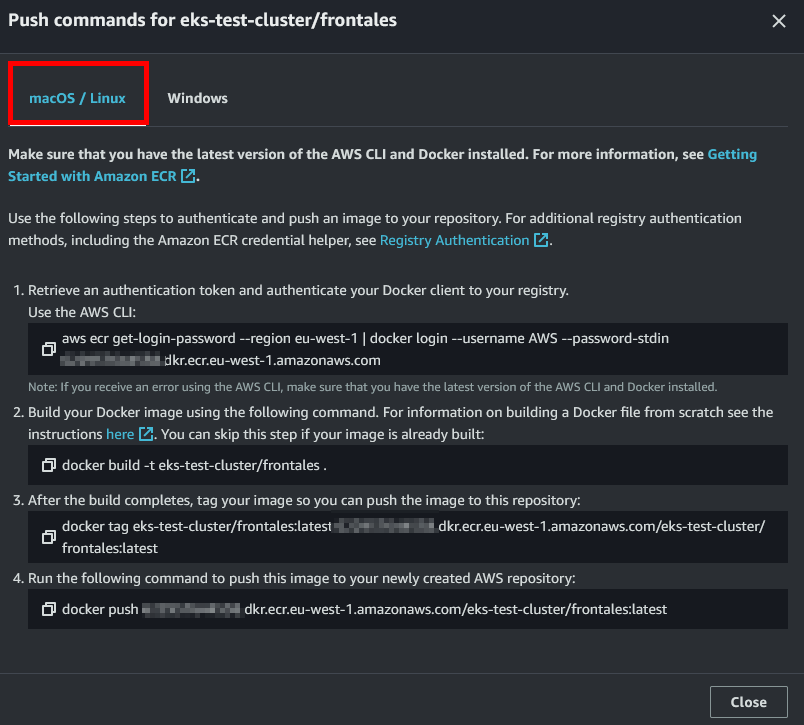
- A pesar de que estemos en windows, ejecutaremos los comandos que nos proporciona para linux (es posible que necesites tener instalado Windows Subsystem for Linux).
- Abriremos el visual studio code en la carpeta donde hemos descomprimido el ZIP, y abriremos un nuevo terminal y nos posicionaremos a la carpeta Image de la carpeta Frontend.
Para ello iremos a Terminal (1) y le daremos a “New terminal” (2), posteriormente cambiaremos a la carpeta de Image ejecutando “cd .\Frontend\Image”.
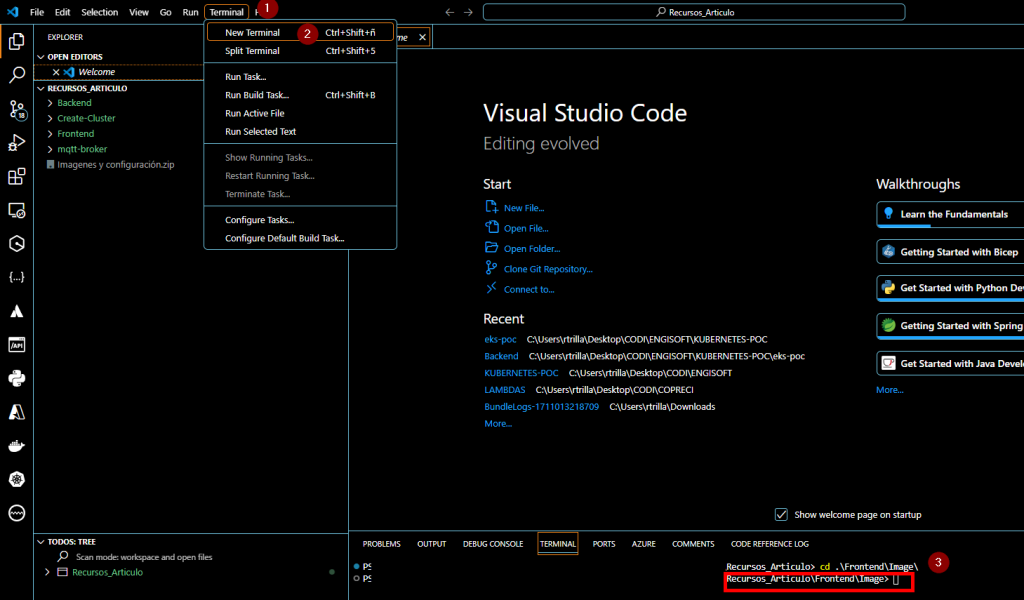
- Ejecutaremos la primera instrucción de los comandos que nos proporciona ECR. Si nos devuelve un error, revisa con qué usuario estás usando en AWS CLI y revisa que docker se esta ejecutando.


- Posteriormente, compilaremos la imagen con docker.


- Posteriormente, taguearemos la imagen que acabamos de crear para que tenga el nombre adecuado para el repo.


- Finalmente, haremos un push para subir la imagen a ECR.

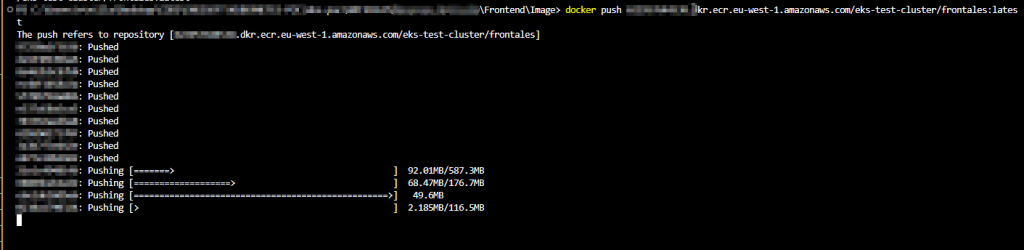
- Una vez haya acabado de subir la imagen, refrescaremos la web de ECR y ya nos tendria que salir allí la imagen.

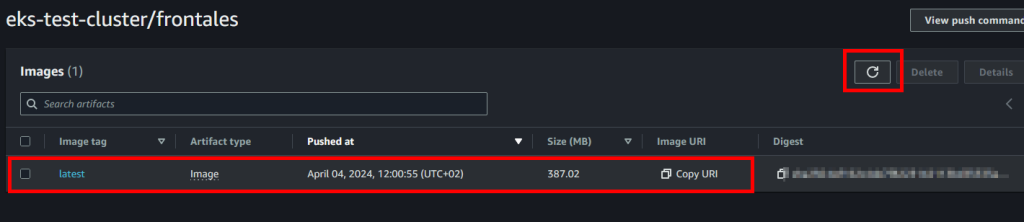
- Tendremos que repetir estas acciones con los otros 2 repos e imágenes para poder tenerlo todo preparado para desplegar nuestro clúster de EKS.
4. Creando los node groups/fargate groups en EKS
Importante: Esto solo lo tienes que hacer si has creado el clúster a través de la consola de AWS, de lo contrario ya estaran creados!
Los Node Groups o Fargate groups de EKS són los grupos de recursos (CPU y RAM) donde se van a ejecutar nuestros pods, es decir, nuestro código. Más abajo explicaremos las diferencias entre estos dos grupos/modalidades de obtener los recursos para nuestra ejecución.
4.1 Asignar IAM Principal
Para poder ver todo lo que pasa dentro de nuestro clúster de EKS, deberemos asignar un IAM Principal, que nos permitirá ver desde la consola de EKS de AWS toda la información.
Para ello haremos lo siguiente:
- Si entramos en el servicio EKS y vamos al apartado de clusters, nos saldra un banner azul en la parte superior que nos indicara que no tenemos ningún IAM Principal. Le damos al link para crear uno.
- Una vez dentro dejaremos seleccionado StarterRole y de Type Standard.
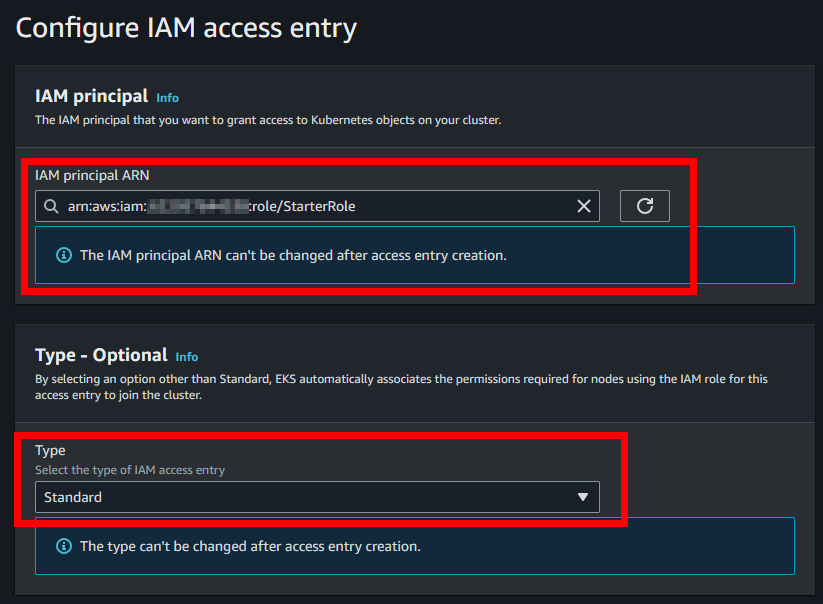
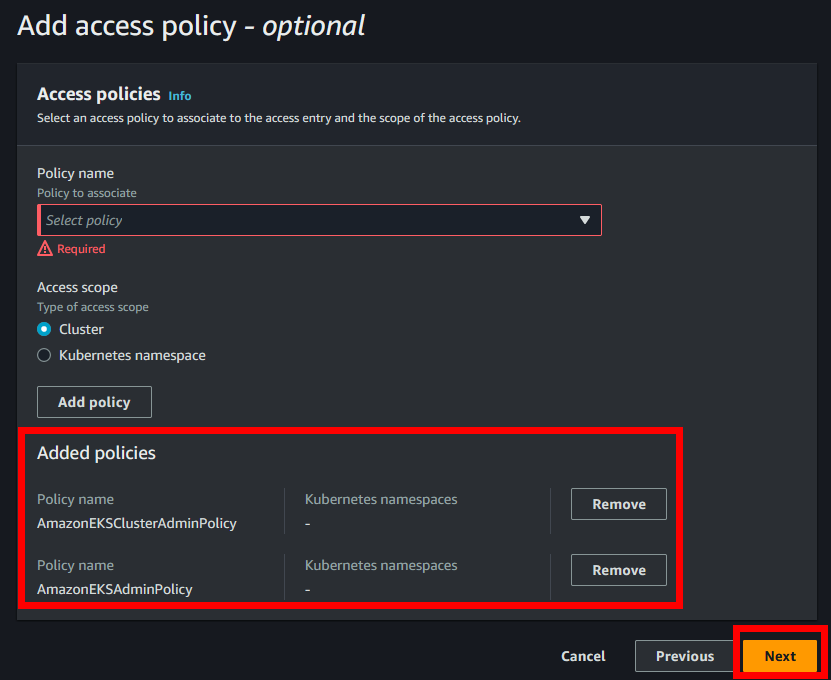
- En Access Policy seleccionaremos la política “AmazonEKSClusterAdminPolicy” y le daremos al botón “Add policy”, después seleccionaremos la política “AmazonEKSAdminPolicy” y le daremos otra vez a “Add policy”. Una vez hecho esto le daremos a “Next”.
4.2 Modalidad EC2 vs Fargate en EKS
Antes de poder poner en marcha nuestro clúster de EKS, deberemos decidir que modelo de aprovisionamiento de recursos utilizaremos entre las opciones que nos ofrece AWS.
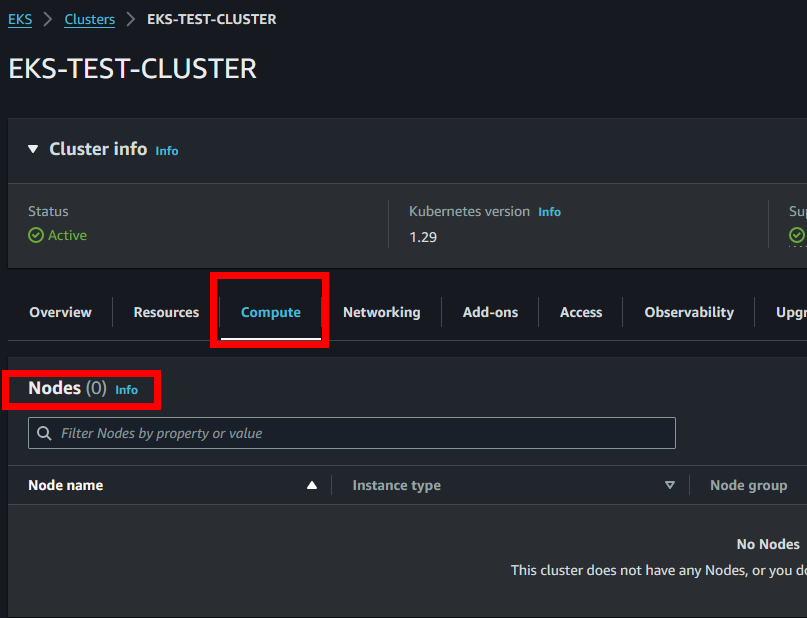
Si nos vamos al apartado de “Compute” veremos que hay 2 principales apartados, “Node groups” y “Fargate profiles”. Un “Node Group” utilizará el servicio EC2 para aportar potencia computacional al clúster, y, por el contrario, “Fargate profiles” utilizará el servicio AWS Fargate para aportar esa potencia computacional.
Como decidir cuál es mejor:
- Si utilizamos “Node Groups” es decir, EC2’s, los recursos disponibles vienen definidos el tipo de máquinas disponibles en AWS y acostumbran a salir más baratas, eso sí, si eres capaz de utilizar todos los recursos de la máquina.
- Si utilizamos “Fargate Profiles” es decir, Fargate, al contrario que EC2, es un servicio donde tú le indicas los recursos que necesitas (serverless) y ya se encarga el de reservar los recursos que necesites sin necesidad de preocuparte que maquinas vas a necesitar, etc. Eso sí, su coste es un bastante más elevado, pero ofrece más flexibilidad.
- “Por que no los dos”, puede ser que dentro de tu clúster haya workloads que se adapten mejor a las EC2 que AWS proporciona, o que, por el contrario, no se adapten nada a ellas. Con la ayuda de distintos tags puedes indicar que el Workload A corra en Fargate y que el Workload B corra en instancias EC2.
Por lo tanto, todos los modos tienen sus ventajas y sus inconvenientes, por lo que dependerá de tu aplicación final como lo quieras hacer. Para ello AWS ha puesto a disposición un listado de las diferencias entre modalidades Amazon EKS nodes.
En esta PoC vamos a usar los Node Groups (EC2) pero, si en un futuro estás creando un clúster de Kubernetes y no sabes que escoger, te recomendamos que le eches un vistazo a AWS Pricing Calculator donde podrás realizar un cálculo bastante exacto del coste que va a suponer cada opción.
4.3 Creado un node group en EKS
Para desplegar nuestra aplicación, vamos a crear un Node Group por micro-servicio, es decir, uno por el broker, otro para la API, y un último para el backend. A pesar de que no tendremos tráfico suficiente para hacer que la máquina consuma todos los recursos, lo vamos a hacer así para probar también que la comunicación interna entre máquinas funciona y que no nos tenemos que preocupar por el cambio de ips de nodos, etc, sino que iremos por url interna.
Vamos a ello:
- Iremos al apartado de “Compute” y seleccionaremos “Add node group”.
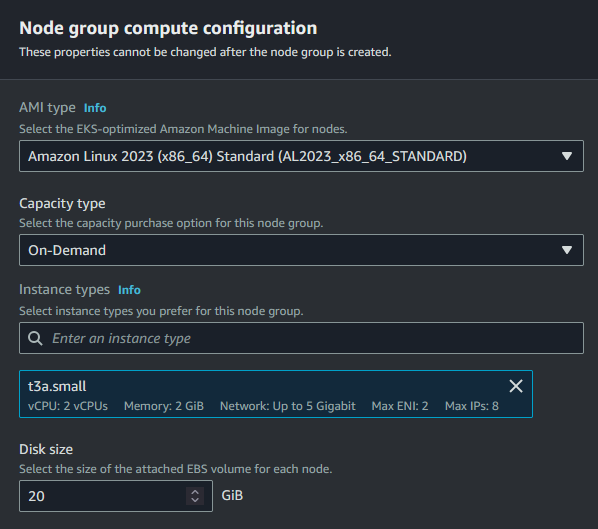
- Seleccionaremos la AMI “Amazon Linux 2023” (como en teoría la imagen no debería importar, selecciona la opción más nueva de Amazon Linux). En el apartado de Capacity dejaremos seleccionado “On-Demand” (está disponible Spot, pero en este artículo no nos aporta nada). En el apartado de “instance type” y pondremos la t3a.small. En el apartado de “Disk size” lo dejaremos a 20GB que es lo mínimo que pide Amazon Linux 2023.
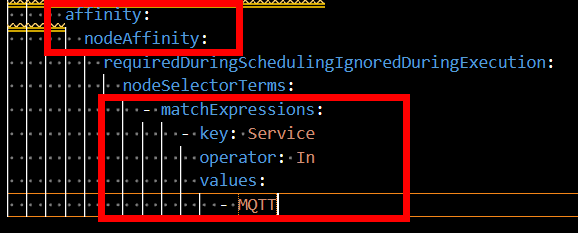
- En el apartado de Kubernetes TAGS, añadiremos las siguientes (una por cada node group, por ejemplo, si estamos creando el node group del broker mqtt, solo añadiremos “Service” “MQTT”, nada más. Tiene que estar exactamente como los ficheros de configuración):
| Servicio | Key | Value |
| MQTT-BROKER | Service | MQTT |
| FRONTEND | Service | Frontend |
| BACKEND | Service | Backend |
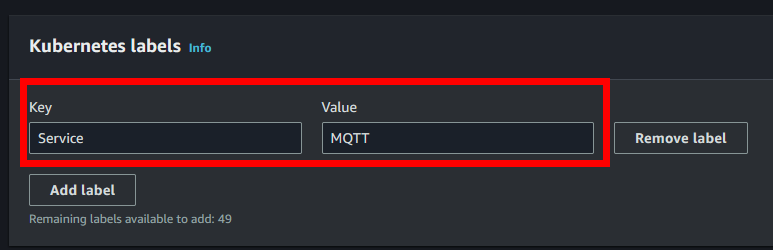
- En el apartado de “Node Group scaling configuration”, dejaremos en “desired” (número de nodos deseados) a 1, el “Minimum” a 1 y el “Maximum” a 2 nodos.
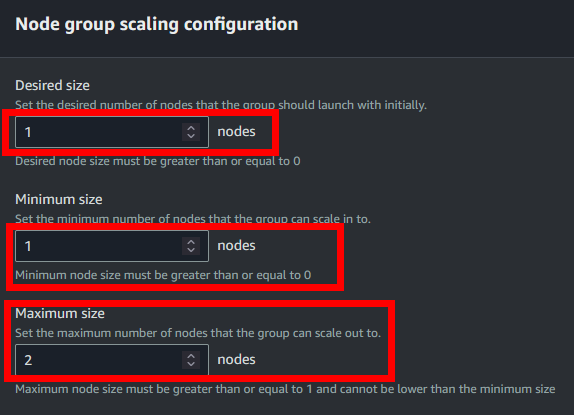
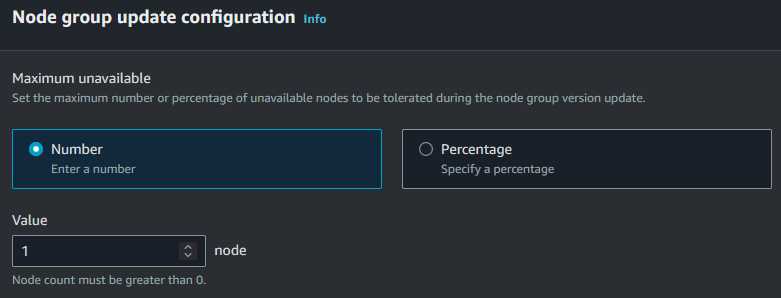
- Le daremos a continuar, y en el siguiente apartado ajustaremos el procedimiento de Update. En este caso le diremos que el número máximo de nodos que pueden estar caídos (osea aplicando el update) puede ser 1.
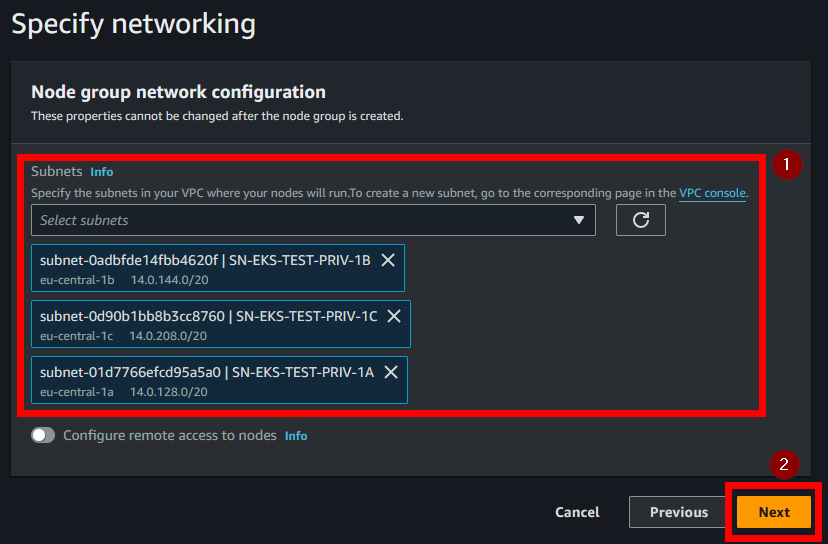
- En el apartado de “Network”, deseleccionaremos las que nos vienen marcadas por defecto y dejaremos solo seleccionadas las privadas.
- Revisamos y le damos a “crear”. Una vez hecho esto, el node Group pasará a estado Creating.

- De mientras, iremos creando los distintos Node Groups que aún nos faltan.
- Una vez terminado de crearse, debería pasar a un estado tal que así.

5. Conclusión
En este articulo, hemos visto como generar imagenes con docker, subir esas imagenes a ECR para que luego puedan ser usadas por los Node Groups de EKS.
También hemos creado nuestros Node Groups, aprendiendo sobre las opciones de las que disponemos para dar potencia computacional a nuestro clúster y las principales diferencias que lleva un modelo sobre el otro.
En el siguiente artículo ya vamos a crear la Base de Datos y probaremos que nuestra aplicación que se ejecuta en este clúster funciona.
Artículo anterior: 3. Vamos a crear un clúster
Siguiente artículo: 5. Creando el RDS (base de datos) y probando la PoC